[DB] 데이터 모델 & 성능
데이터 모델과 성능
이상현상
정규화를 살펴보기 전에 이상현상(Anomaly)에 대해서 알아보자
- 삽입 이상
- 불필요한 데이터를 추가해야지만, 삽입이 가능한 상황
- 갱신 이상
- 일부만 변경하여, 데이터가 불일치 하는 모순이 발생하는 상황
- 삭제 이상
- 튜플 삭제로 인해 꼭 필요한 데이터까지 함께 삭제되는 상황
정규화
데이터의 일관성,최소한의 중복,최대한의 데이터 유연성을 위한 방법으로, 데이터를 분해하는 과정을 말한다.- 데이터 중복을 제거하고 데이터 모델의 독립성을 확보한다.
- 정규화를 하면 비즈니스 변화가 발생해도 데이터 모델의 변경을 최소화할 수 있다.
- 1~5 정규화까지 있으며, 제3정규화까지만 수행한다.
정규화 절차

함수의 종속성이란?
- X, Y가 있을 때, X가 변할 때 Y도 변한다면 Y는 X에 함수적으로 종속된다고 표현한다.
- X->Y이면 Y는 X에 함수적으로 종속
- 제1정규화는 함수적 종속성을 근거로 시행한다.
제1정규화
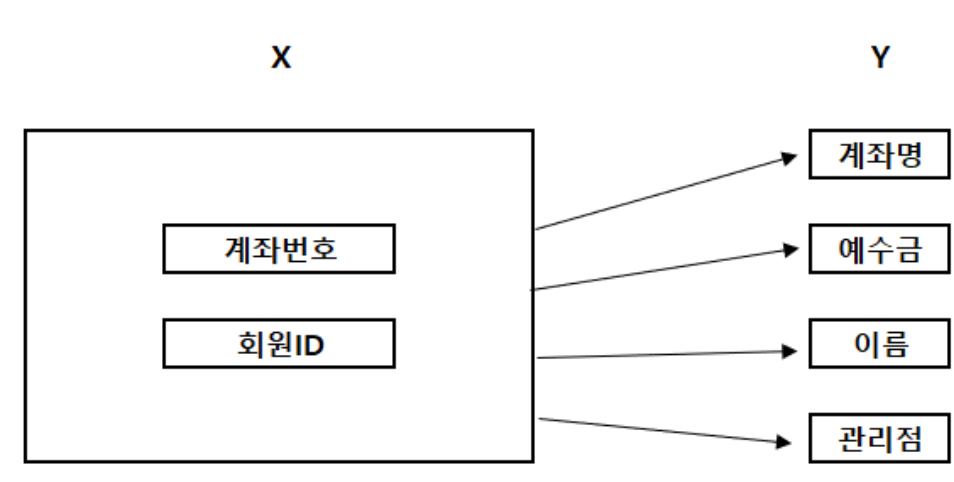
위 그림을 보면 테이블 X가 Y의 column들을 함수적으로 종속하고 있다. X의 계좌번호 하나로 유일성을 만족하지 못한다고 가정하고 계좌번호와 회원ID를 기본키로 설정한 모습이다. 이처럼 기본키를 잡는 것이 제1정규화이다.
제2정규화
제2정규화는 부분 함수 종속성을 제거하는 과정이다. 부분 함수 종속성은 기본키가 2개 이상의 column으로 구성되는 경우에만 발생한다. 때문에 기본키가 1개라면 제2정규화는 넘어간다.
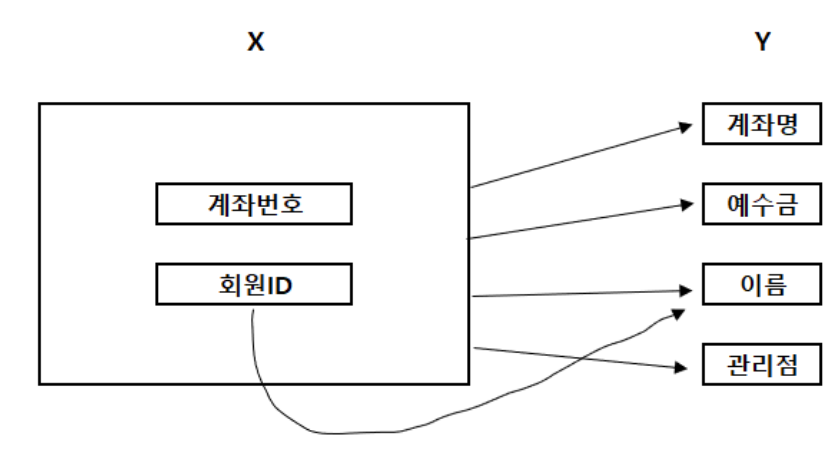
위 그림에서 기본키의 회원ID가 변경되면 이름이 변경된다. 즉 회원ID가 이름을 함수적으로 종속하고 있다. 이런 경우를 부분 함수 종속성이라고 한다. 부분 함수 종속성이 발생하면 분해를 통해 제거해야 한다.
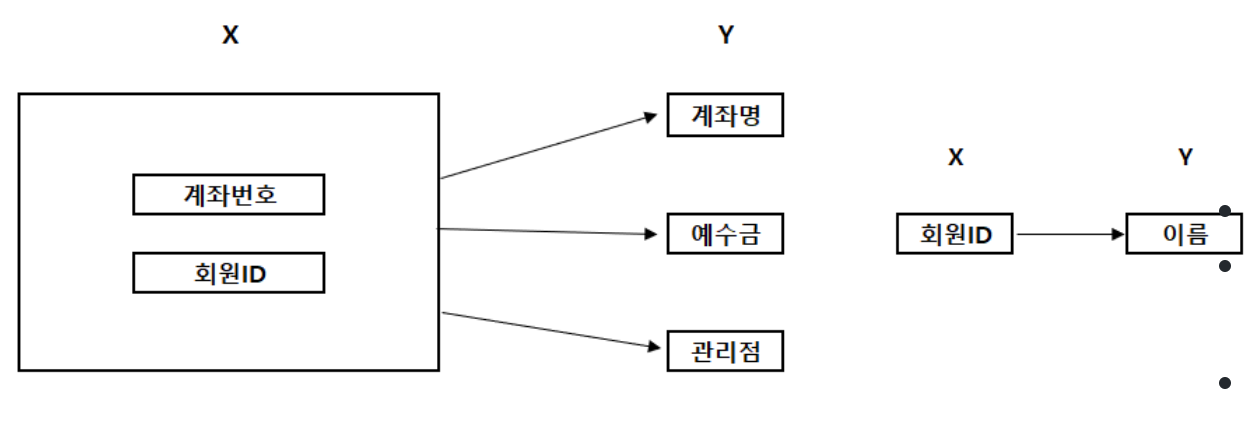
이처럼 테이블을 하나 도출된다.
제3정규화
제3정규화는 이행 함수 종속성을 제거하는 과정이다. 이행 함수 종속성이란 기본키를 제외한 칼럼간의 종속성이 발생하는 것을 말한다. 제3정규화는 제1, 제2 정규화를 마치고 수행한다.
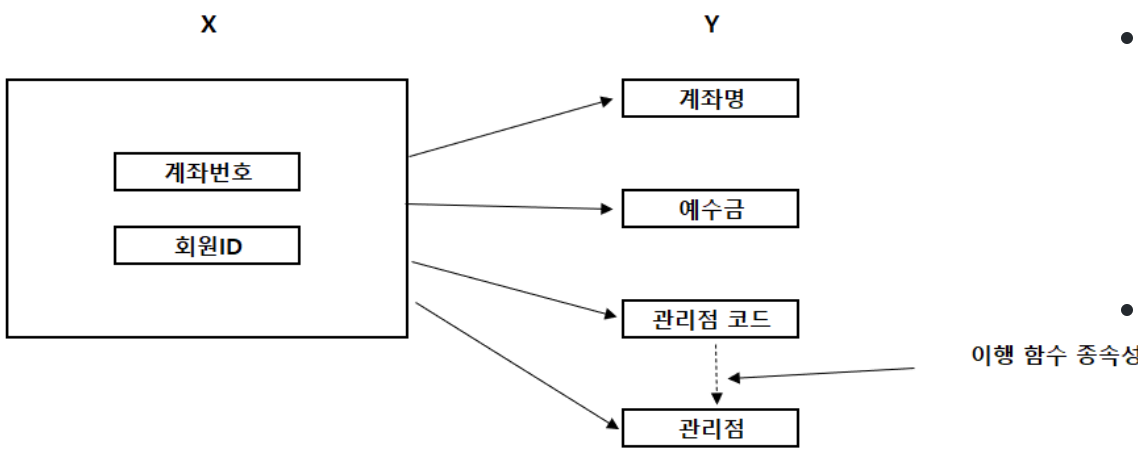
관리점 코드가 바뀌면 관리점이 바뀐다. 다시 말해서 관리점이 관리점 코드에 함수적으로 종속된다. 때문에 관리점 테이블이 도출되고 관리점 코드가 기본키가 된다.
정규화와 성능
정규화를 수행하는 것이 항상 좋지는 않다.
정규화를 수행하면 테이블이 분해되고 데이터의 중복이 제거되기 때문에 데이터 모델의 유연성은 높아지지만 데이터를 조회할 때 조인을 유발하기 때문에 CPU와 메모리를 많이 사용하게 된다.
조인으로 인한 성능 문제는 반정규화를 통해서 해결할 수 있다. 하지만 반정규화는 데이터를 중복시키기 때문에 또 다른 문제가 있다.

위 테이블을 보면 칼럼이 계속 증가할 때, 조인이 최소화되기 때문에 조회를 빠르게 할 수 있다. 하지만 column이 많아지면 1개의 행의 크기가 데이터베이스 관리 시스템의 입출력 단위인 블록의 크기를 넘어설 수 있다. 그렇게 되면 1개의 행을 읽을 때 여러 개의 블록을 읽어야 한다.
이는 디스크 입출력 횟수 증가를 유발하고 성능이 오히려 떨어진다.
반정규화
- 데이터베이스 성능 향상을 위해 데이터 중복을 허용하고 조인을 줄이는 데이터베이스 성능 향상 방법
- 조인을 줄여서 조회 성능이 좋아지지만, 데이터 모델의 유연성은 떨어진다.
- 반정규화를 수행하는 경우는?
- 다량의 범위를 자주 처리할 때
- 특정 범위의 데이터만 자주 처리하는 경우
- 요약/집계 정보가 자주 요구되는 경우
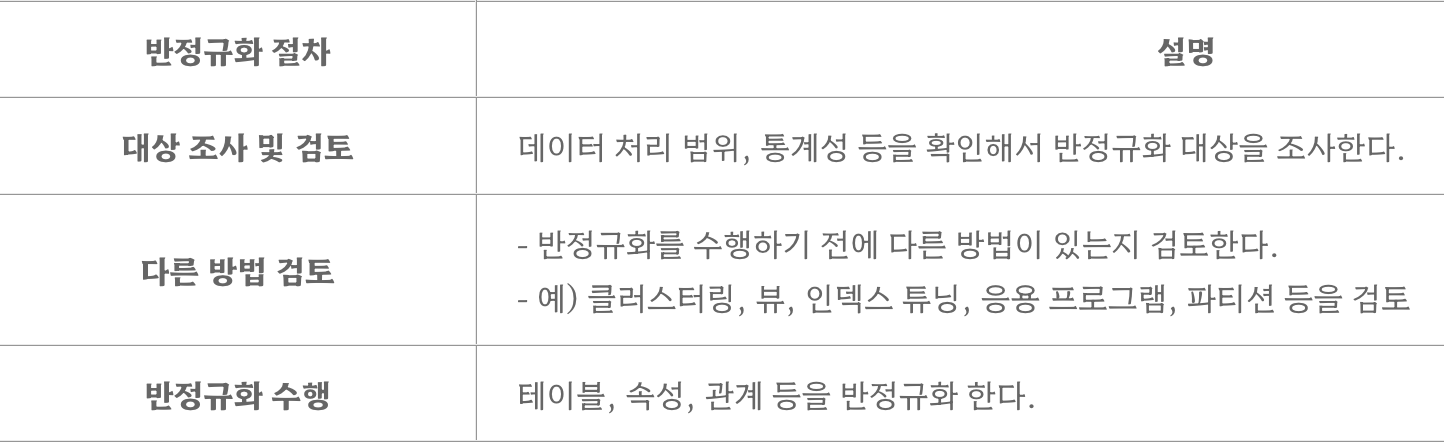
- 절차
분산 데이터베이스
- 중앙 집중형 데이터베이스 : 데이터베이스 시스템 구축 시, 1대의 물리적 시스템에 데이터베이스 관리 시스템을 설치하고 여러 명의 사용자가 데이터베이스 관리 시스템에 접속하여 데이터베이스를 사용하는 구조
- 분산 데이터베이스 : 물리적으로 떨어진 데이터베이스를 네트워크로 연결하여 단일 데이터베이스 이미지를 보여주고, 분산된 작업 처리를 수행하는 데이터베이스
분산 데이터베이스의 투명성 종류

분산 데이터베이스 장단점
