[운영체제] 프로세스 스케줄링
CPU 스케줄링
정의
CPU 스케줄링은 프로세스가 작업을 수행할 때, 언제 어떤 프로세스에게 CPU를 할당할지를 결정하는 작업이다.
분류
비선점형 알고리즘
비선점형 알고리즘은 한번 프로세스가 실행되면 해당 프로세스가 종료되거나 CPU를 자진해서 반납하는 상황이 아니라면 계속 실행되게 하는 알고리즘이다.
선점형 알고리즘과 달리 문맥 교환에 따른 오버헤드는 없지만 사용자에게 동시에 작업이 수행되는 느낌을 줄 수 없다.
종류
FCFS (First Come First Served)
말 그대로 준비큐에 먼저 도착한 순서대로 프로세스가 실행된다.
예시를 보자. (여기서 Burst Time은 CPU 사용 시간이다. 임의로 단위는 T라고 하자)

세 개의 프로세스 P1, P2, P3가 순서대로 준비큐에 도착했을 때 어떻게 실행되는지 확인해보자.

우선 준비큐에 가장 먼저 도착한 P1이 CPU를 24T만큼 사용한다. 그리고 준비큐에 두번째로 도착한 P2가 3T만큼 CPU를 가지고 실행한다. 마지막으로 P3가 3T만큼 실행된다.
예시에서 볼 수 있듯이 P2, P3는 CPU 실행시간이 짧음에도 불구하고 P1의 실행을 기다려야 하기 때문에 대기시간이 길어지는 것을 볼 수 있다.
이렇게 작업 시간이 긴 프로세스가 먼저 큐에 도착하여 다른 프로세스의 실행 시간이 전부 늦어져 효율성이 떨어지는 현상을 콘보이 효과(Convoy effect)라고 한다
SJF (Shortest Job First)
SJF는 CPU burst가 가장 낮은 프로세스에게 CPU를 먼저 할당하는 알고리즘이다.
예시를 보자. (여기서는 P1, P2, P3, P4가 전부 메모리에 올라가있는 상태라고 가정하자.)


CPU burst가 짧은 순으로 P4, P1, P3, P2가 실행되는 것을 확인할 수 있다. 위의 경우 평균 대기 시간은 (3 + 16 + 9 + 0) / 4 = 7이 된다.
SJF는 비선점 알고리즘이기 때문에 중간에 준비큐에 CPU burst가 더 짧은 프로세스가 들어와도 중간에 실행되던 프로세스에게서 CPU를 뺏을 수 없다. 그리고 CPU를 얼만큼 사용할지는 실행 전에는 알 수 없기 때문에 이전에 실행한 로그를 토대로 추측한다.
기본적으로 CPU burst가 작은 프로세스를 우선적으로 실행하기 때문에 CPU burst가 긴 프로세스는 계속해서 실행이 안될 수 있다. 이를 기아 현상(starvation)이라고 한다. (이는 Aging을 통해 해결할 수 있다.)
- Aging : 시간이 지날수록 우선순위를 올려주는 기법
HRN (Highest Response Ratio Next)
HRN은 대기 시간과 처리 시간을 모두 고려하여 CPU를 할당하는 방식이다.
우선순위 = (대기 시간 + 처리 시간) / 처리 시간
선점형 알고리즘
선점형 알고리즘은 실행 상태에 있는 프로세스의 작업을 강제로 중지하고 새로운 프로세스에게 CPU가 넘어갈 수 있는 알고리즘이다.
선점형 알고리즘의 경우 문맥 교환으로 인해서 오버헤드가 증가하게 된다. 하지만 사용자에게 동시(Concurrency)에 여러 작업이 수행되는 것처럼 보이게 하기 위해서 대부분의 운영체제는 선점형 알고리즘을 사용하여 스케줄링을 수행한다.
종류
RR (Round Robin)
한 프로세스가 할당 받은 시간(time slice)동안 작업을 수행하다가 작업을 완료하지 못하면 준비 큐의 맨 뒤로 가서 차례를 기다리는 방식이다.


위 그림의 경우 time slice = 4이다. 즉 프로세스가 CPU를 4 burst time 실행하면 다른 프로세스로 CPU가 넘어간다는 것이다.
P1이 우선 4만큼 실행한 시점에서 20만큼의 CPU burst가 남는데 이를 끝마치지 않고 CPU가 P2 프로세스로 넘어가는 것을 볼 수 있다. P2는 CPU를 3만큼 실행하고 자진해서 CPU를 P3에게 넘겨준다. 그리고 P3도 마찬가지로 3만큼 실행하고 P1으로 CPU를 넘긴다.
이후 준비큐에 P1을 제외한 다른 프로세스가 존재하지 않기 때문에 P1이 계속해서 실행된다.
SRT (Shortest Remaining Time)
앞에서 살펴본 SJF에서 중간에 CPU를 뺏을 수 있다는 것만 추가됬다고 생각하면 된다.
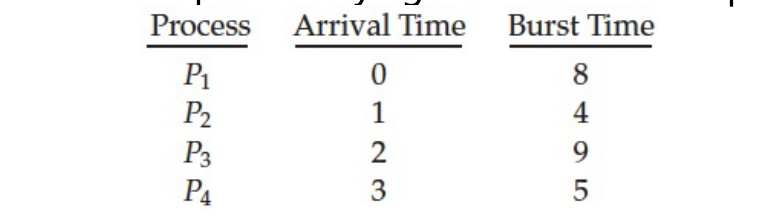
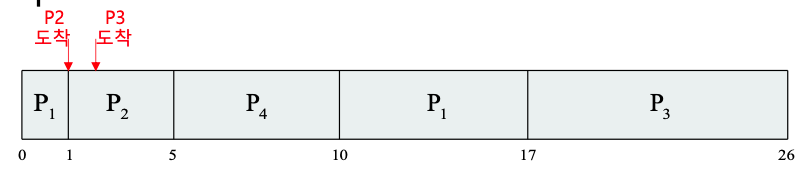
P1이 0T에 준비큐에 도착한 시점에는 P1을 제외한 다른 프로세스가 없기 때문에 바로 실행된다.
1T에 P2가 도착했는데 이 때 P2의 Burst Time(4)가 P1의 남은 Burst Time(7)보다 짧기 때문에 사용하던 CPU를 뺏어서 P2가 실행된다.
2T에 P3가 도착했지만 P2의 남은 Burst Time(3)보다 길기 때문에 P2가 그대로 실행된다.
3T에 P4가 도착했지만 P2의 남은 Burst Time(2)보다 길기 때문에 P2가 그대로 실행된다.
이후 5T에 P2의 실행이 끝나서 준비큐에 있는 P1(7), P3(9), P4(5) 중 가장 짧은 P4가 실행된다.
이처럼 SRT에서는 실행중인 프로세스보다 현재 준비큐에 도착한 프로세스의 CPU burst가 더 작은 경우 CPU를 강제로 뺏을 수 있다.
이 경우도 SJF와 마찬가지로 기아 현상(starvation)이 발생할 수 있다.
Multi-Level Feedback Queue
여러 개의 준비 큐를 두고, 각 큐에 우선순위를 부여하여 우선순위가 높은 큐에 있는 프로세스에게 CPU를 할당하는 방식이다.
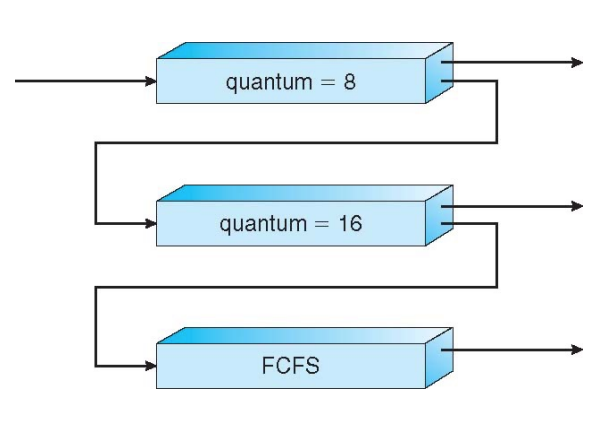
동작
- 우선순위가 높은 큐에 있는 프로세스가 먼저 실행된다.
- 우선순위가 같다면 RR 방식으로 처리된다.
- 프로세스는 준비큐에 들어오면 가장 높은 우선순위를 가진 큐로 들어간다.
- 프로세스가 주어진 time-slice를 모두 소진하면 한 단계 우선순위가 낮은 큐로 들어간다.
- 프로세스가 time-slice 시간 안에 CPU를 다른 프로세스에게 양도한다면 같은 레벨의 큐에 들어간다.
참고
- https://www.youtube.com/watch?v=Bf2YAyFbreI
- Operating System Concepts
- 면접을 위한 CS 전공지식 노트