[트러블슈팅] 커서 기반 페이지네이션
문제 인식
필자는 Palgona 프로젝트에서 상품 리스트 조회 로직 구현을 맡았다.
프로젝트 요구사항에 상품을 최신순, 북마크 순, 최고 입찰가순으로 정렬해서 보여주는 요구사항이 있었다.
처음 구현했을 때는 오프셋 기반의 페이지네이션을 사용해서 구현했는데 팀원분이 커서 기반 페이지네이션을 적용하면 좋을 것 같다는 피드백을 주셨다.
이번 시간에는 커서 기반 페이지네이션 적용 과정에 대해서 설명하고자 한다.
기존 방식의 문제점 (offset based)
단순한 조회 쿼리 (예시)
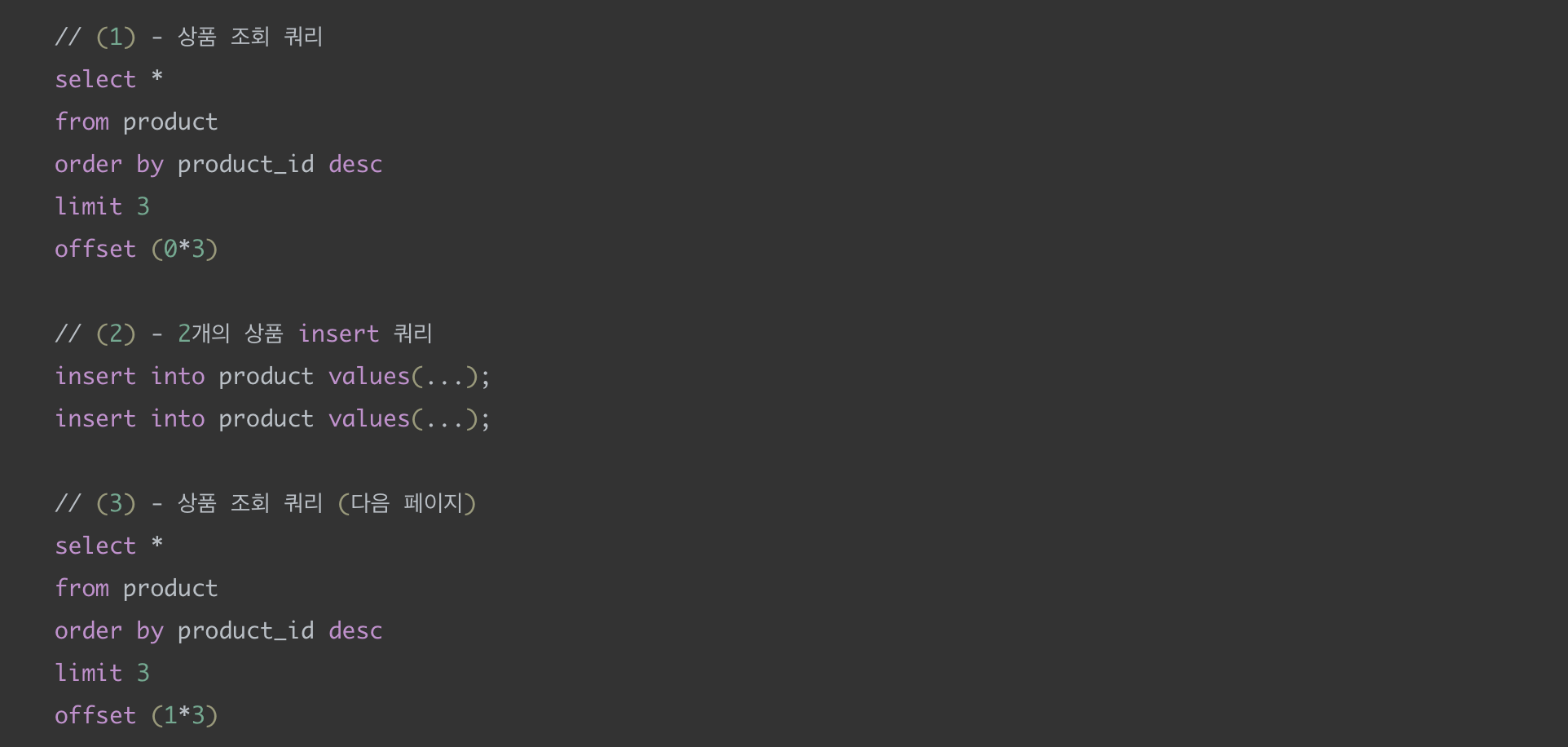
간단한 예시로 설명하겠다. 처음에 상품이 5개가 있다고 가정하자. (id = 1, 2, 3, 4, 5)
(1)에서 쿼리가 나가면 상품 Id가 (5~3)인 상품이 조회될 것이다.
(2)에서 2개의 상품이 추가될 것이다.
(3)에서 다음 페이지를 조회하는데 결과는 상품 Id가 (4~2)인 상품이 조회될 것이다.
→ 데이터가 중복 조회되는 결과가 발생한다. (id = 4, 3 중복 조회)
(뿐만 아니라 조회 중간에 데이터를 삭제하게 되면 어떤 상품은 조회되지 않는 상황도 발생할 수 있다.)
offset 증가에 따른 성능 문제

위 쿼리를 보면 알 수 있듯이 원하는 데이터는 3개인데 앞의 백만 개의 데이터를 다 읽고 3개의 데이터를 가져와야 한다.
뒤에 있는 데이터를 읽을수록 점점 조회 성능이 떨어질 것이라는 것은 자명하다.
→ 커서 기반 페이지네이션 방식을 도입하면 위의 문제를 해결할 수 있다.
커서 기반 페이지네이션
쿼리 예시

커서 기반 페이지네이션 방식은 위와 같이 커서를 기준으로 limit의 개수만큼 조회하는 방식이다.
오프셋 방식처럼 앞의 데이터를 다 읽을 필요가 없기 때문에 뒤쪽의 데이터를 읽더라도 성능 저하가 발생하지 않는다.
커서 데이터만 중복되지 않는다면 성능도 좋고 데이터의 중복도 발생하지 않는다.
이제 간단한 도메인에 대해 소개하고 커서 기반 페이지네이션 방식을 적용한 방법을 소개하겠다.
ERD
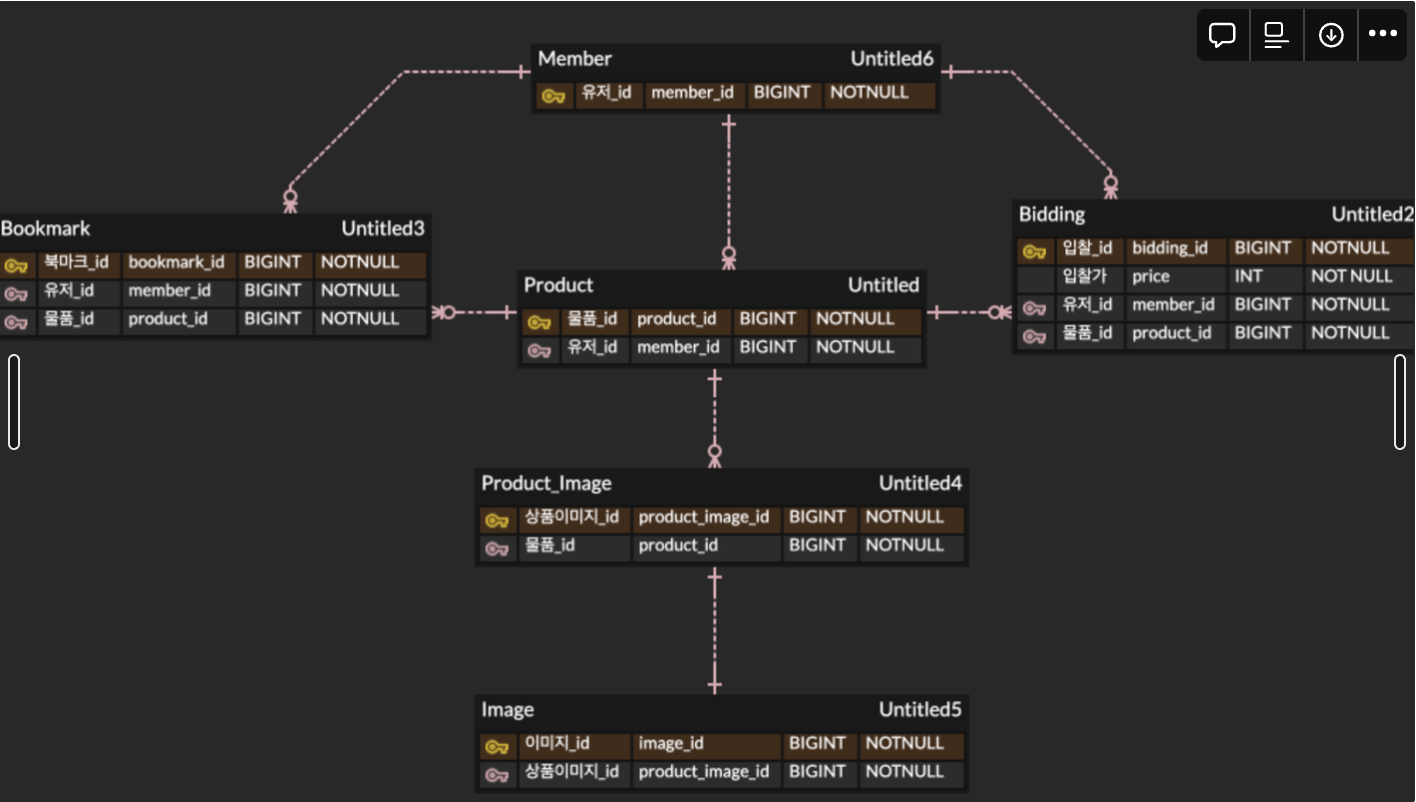
상품 조회에 연관된 Entity만 남겼고 사용되는 필드를 제외하고는 다 걷어냈다.
상품 리스트 조회 API 응답값

모바일 앱을 기준으로 개발했기 때문에 Slice 방식을 채택하여 무한 스크롤이 가능하도록 했다. 이를 위해 위와 같은 응답을 정의했다. 여기서 중요한 부분은 커서인데 뒤에서 설명하겠다.
ProductPageResponse
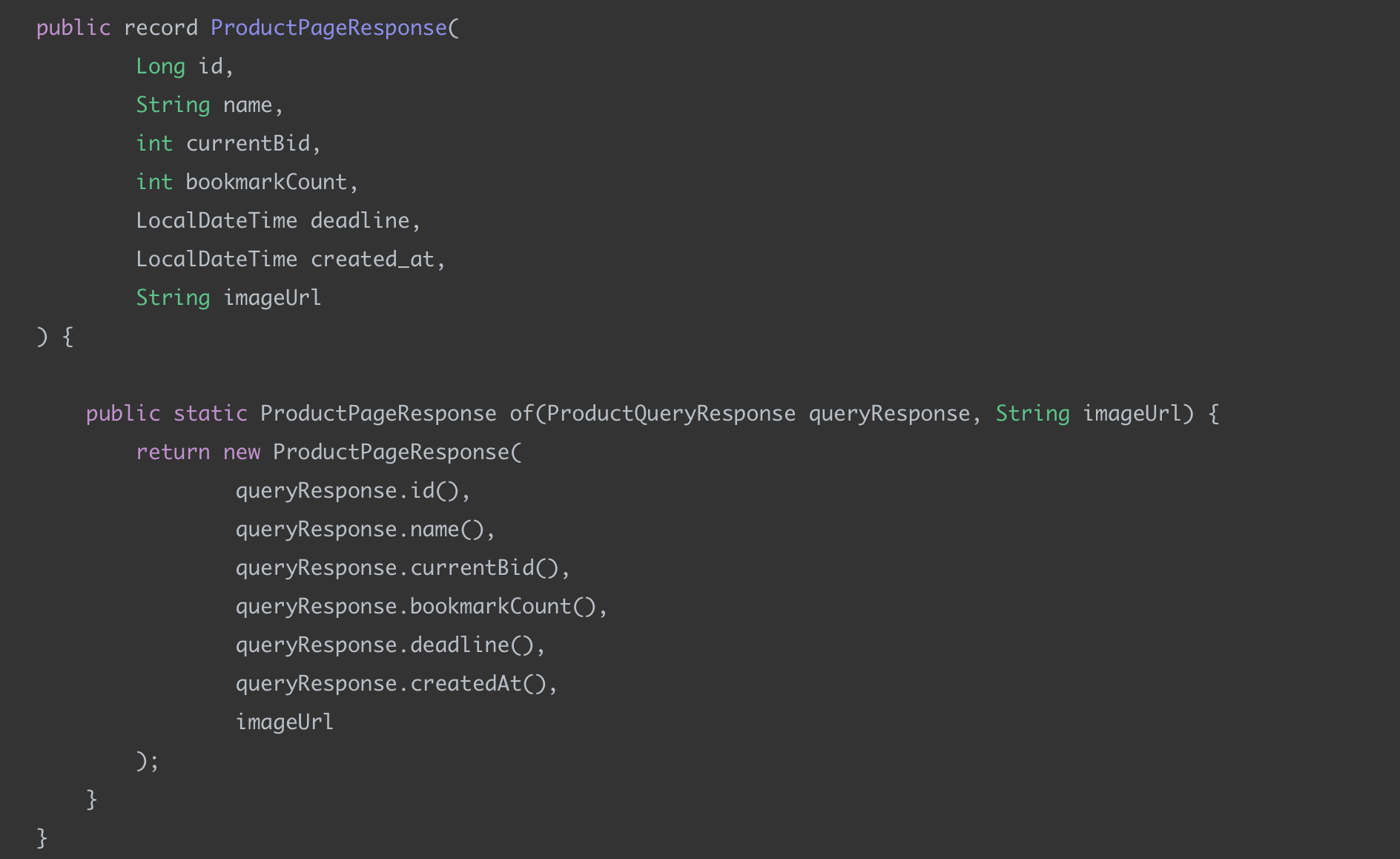
ProductPageResponse가 실제 응답 값이고 이를 SliceResponse로 감싸서 나가게 된다.
이제 조회 쿼리 최적화 과정과 커서 기반 페이지네이션을 어떻게 적용했는지 살펴보자!
커서 (커스텀 커서)
Palgona 프로젝트에서 상품은 최신순, 입찰가순, 북마크 순으로 정렬할 수 있어야 한다.
여기서 최신순을 제외한 입찰가, 북마크 순의 경우 커서 데이터에 중복이 발생할 수 있다.
때문에 별도의 커스텀 커서를 만들어줘야 데이터의 중복이 발생하지 않고 정상적으로 페이지네이션 처리를 할 수 있다.
- 최신순의 경우는 product_id를 커서 데이터로 쓰면 되기 때문에 중복 걱정은 안 해도 된다.
커서 생성 부분
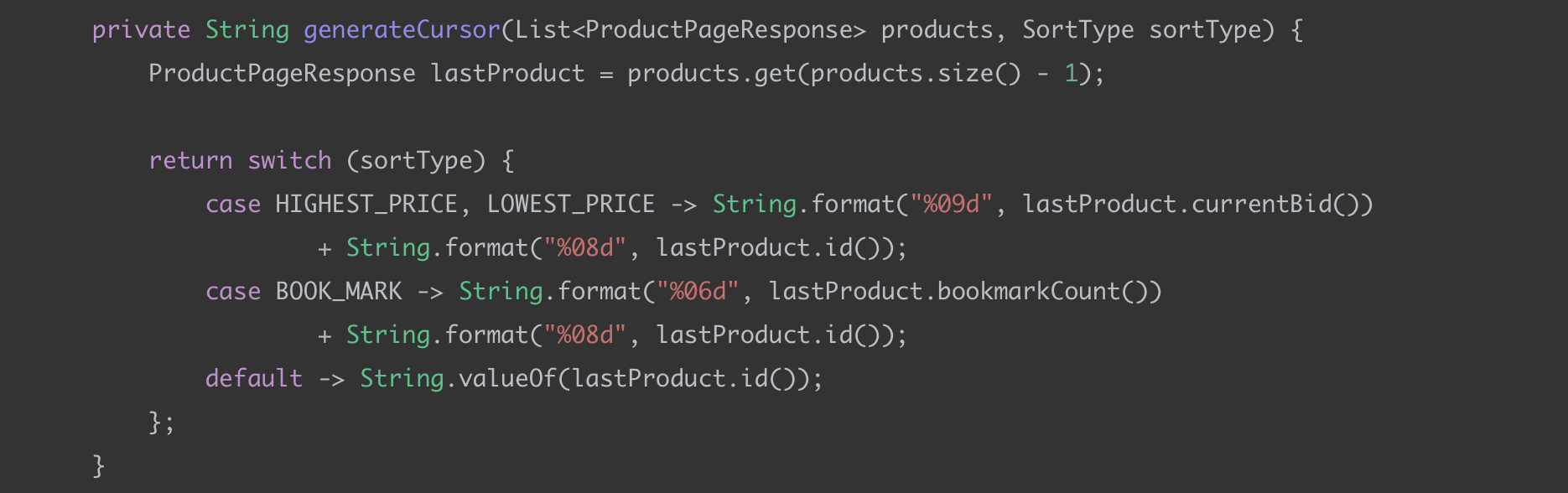
정렬 조건에 따라서 커스텀 커서를 생성하는 부분이다.
CONCAT과 LPAD 함수를 사용하여 유일한 식별자를 만들었다.
생성 예시

입찰가의 경우 9자리로 패딩하고 8자리로 패딩한 product_id와 조합하여 유일한 식별자를 만든다.
→ ex) 입찰가가 70만 원이고 상품 Id가 1이라면 00070000000000001 와 같은 커스텀 커서가 만들어진다.
북마크는 자리수만 다르고 로직은 동일하기 때문에 설명은 생략하겠다.
커서 비교 로직 (isInSearchRange)
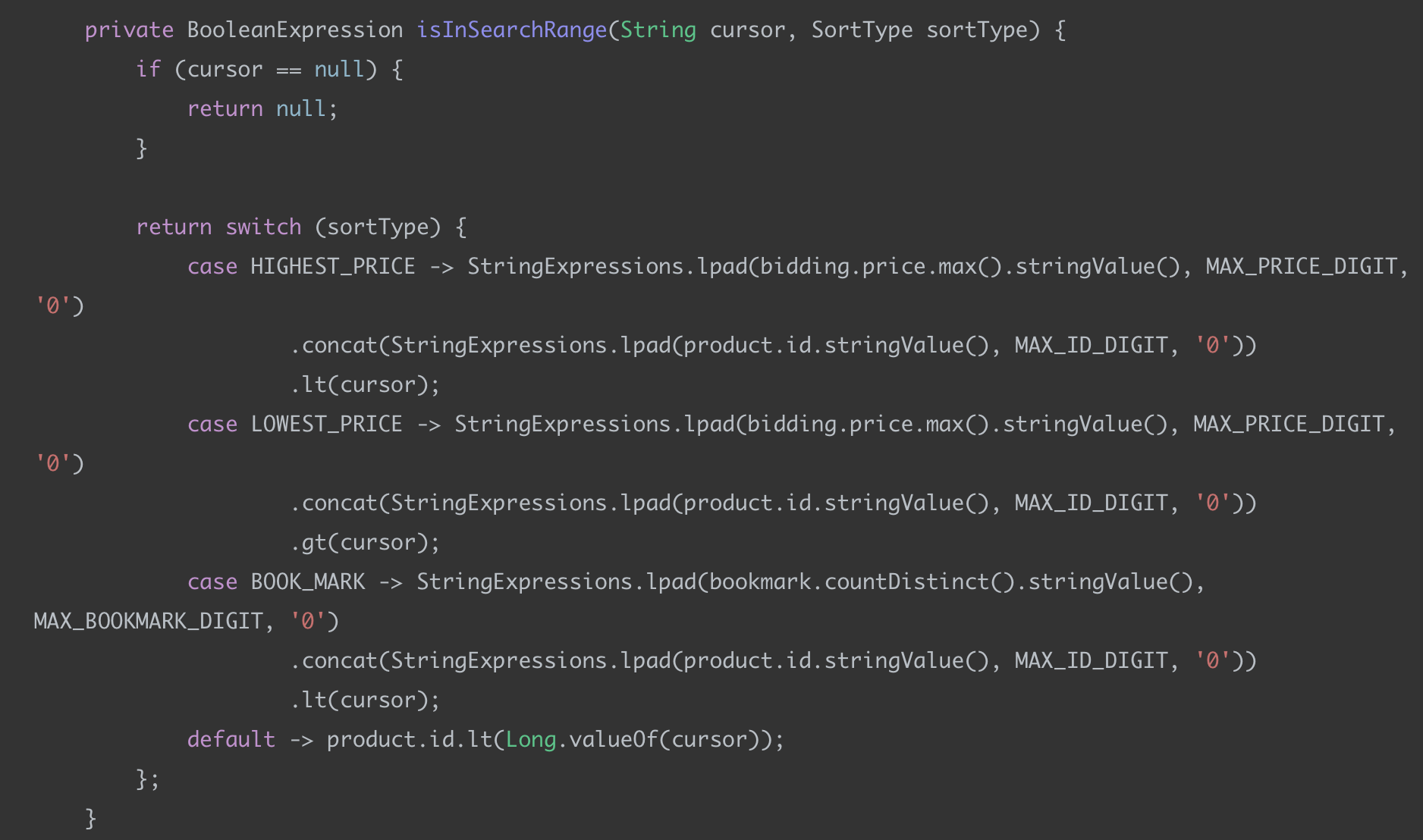
실제로 조회될 데이터인지 판단하는 부분이다.
비교를 위해 값을 패딩하고 Id를 조합해서 값을 만든다. 이를 커서와 비교하여 조회 대상인지 판단한다.
정렬 기준 (createOrderSpecifier)
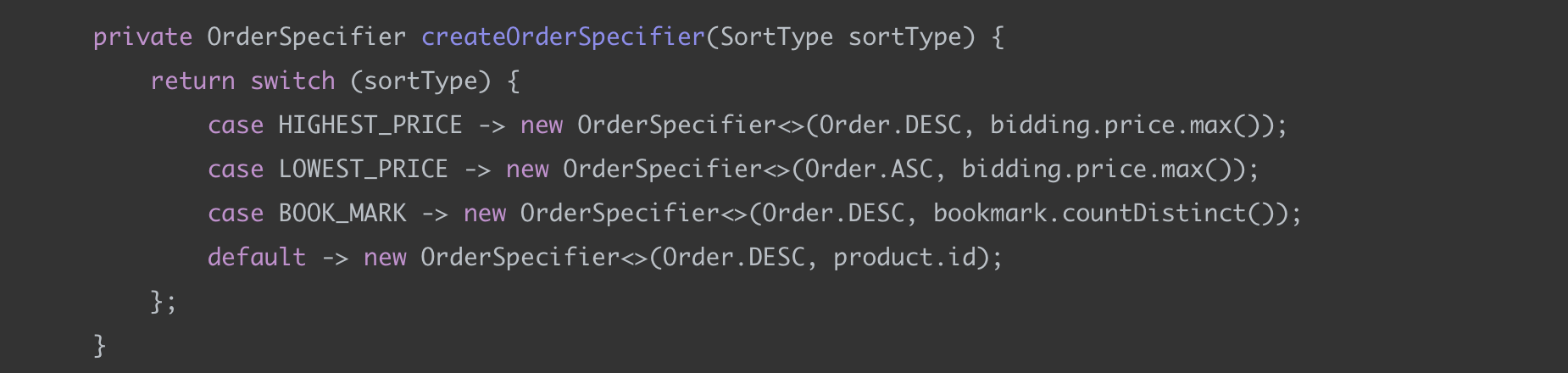
정렬 기준은 Querydsl의 OrderSpecifier 를 사용했다.
상품 리스트 조회 (findAllByCategoryAndSearchWord) - 전체 로직
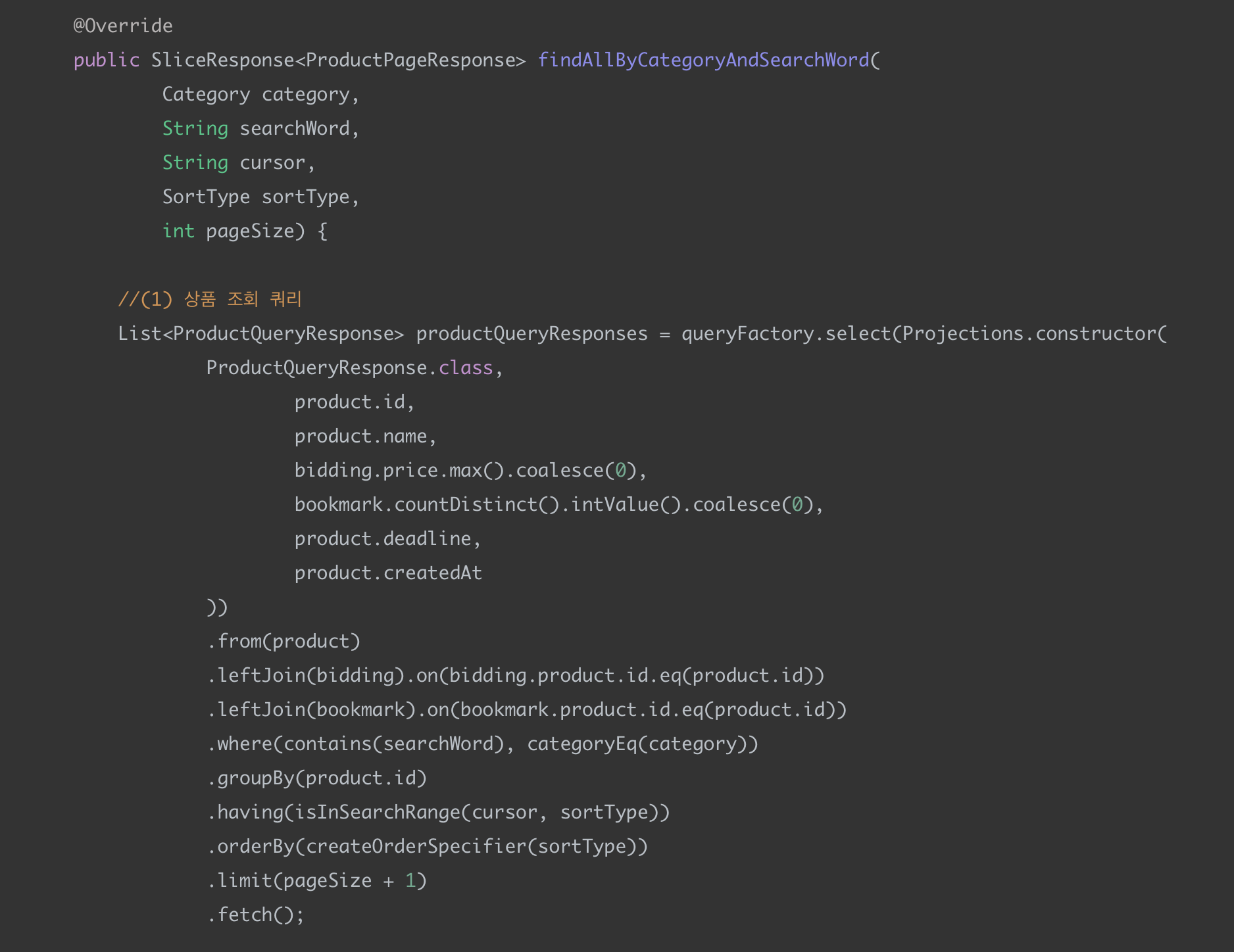

상품 리스트는 총 2번의 쿼리를 통해서 가져왔다. 하나씩 살펴보자!
(1) 상품 조회 쿼리
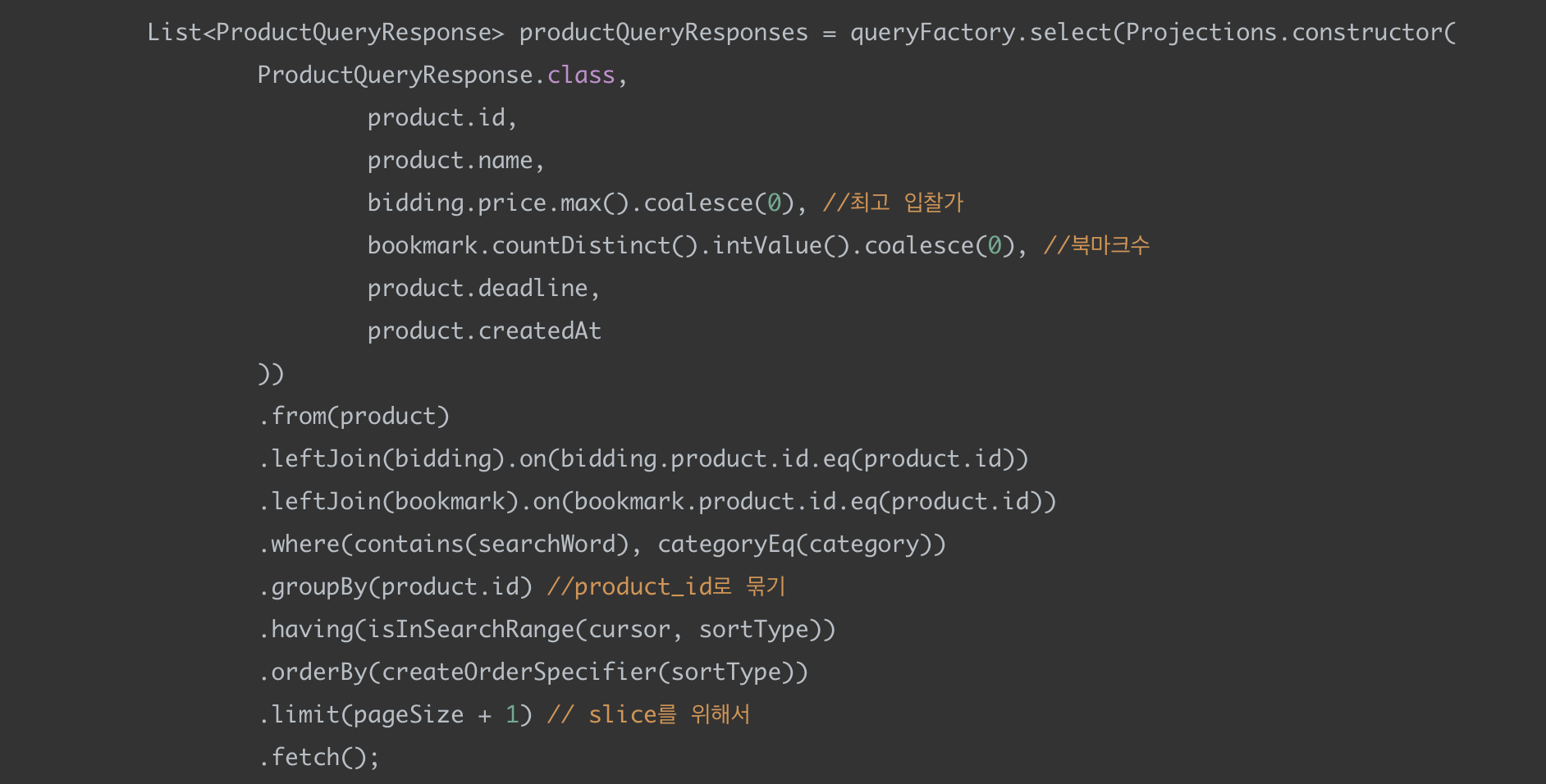
첫 번째 쿼리에서는 Product를 Bookmark, Bidding과 left join해서 최고 입찰가와 북마크 수를 같이 가져온다.
그냥 조회하게 되면 Product가 Bookmark, Bidding과 모두 1:N 관계라서 튜플수가 늘어나게 되서 제대로 페이징 처리를 할 수 없다.
groupBy(product.id) 를 통해서 상품 아이디로 묶어주어 페이징 처리가 제대로 이뤄지게 구현했다.
여기서 상품 이미지를 같이 조회하지 않고 쿼리를 분리한 이유는 대표 사진만 보여줘야 하기 때문이다.
대표 사진은 image_id가 가장 낮은 이미지로 처음으로 등록되는 이미지를 말한다.
만약 쿼리를 나누지 않고 이미지를 같이 가져오게 되면 groupBy(product.id) 를 하면서 최초 이미지를 가져오는 것을 보장할 수 없게 된다.
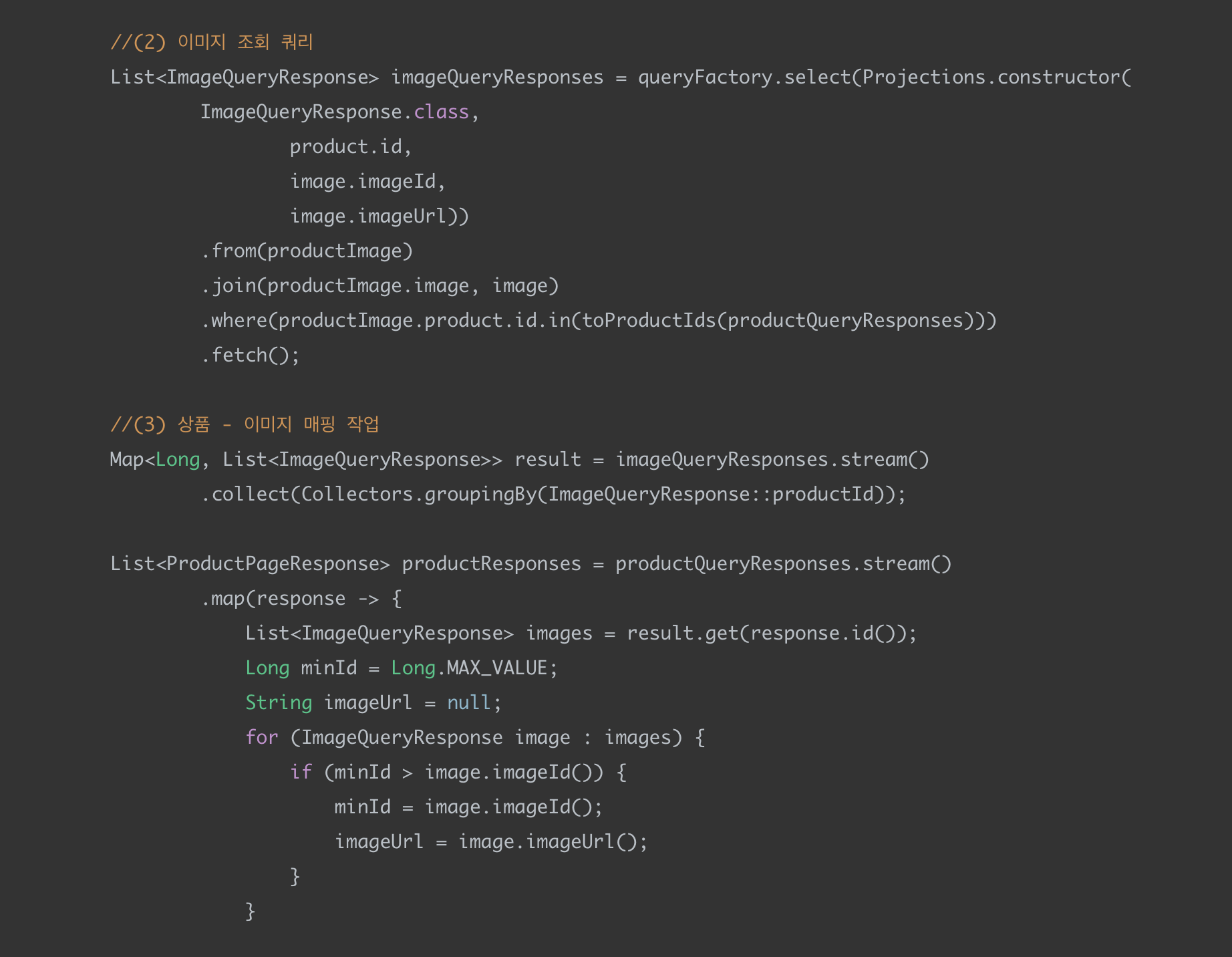
(2) 이미지 조회 쿼리
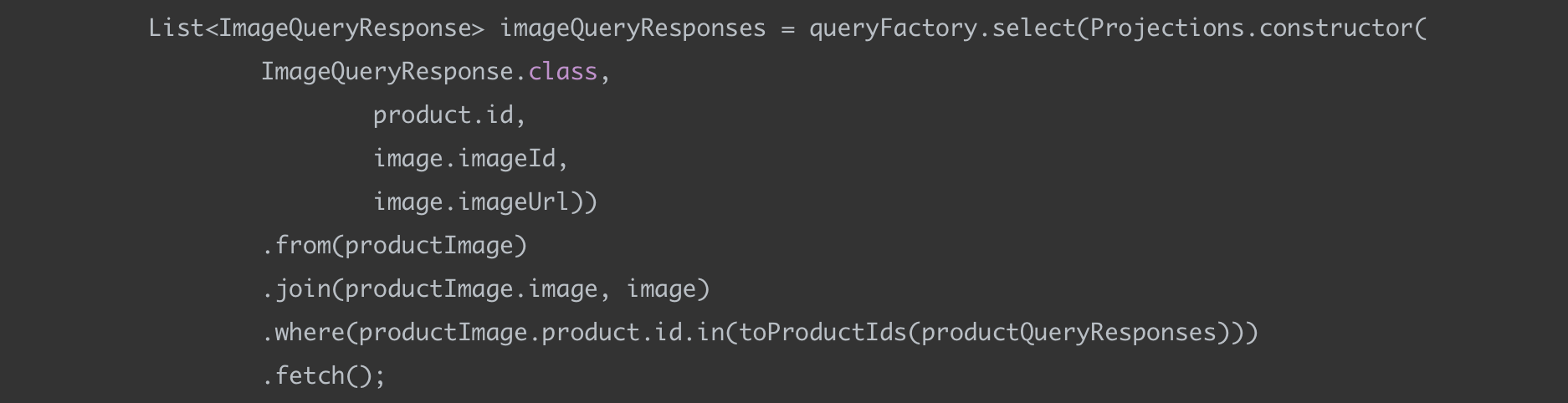
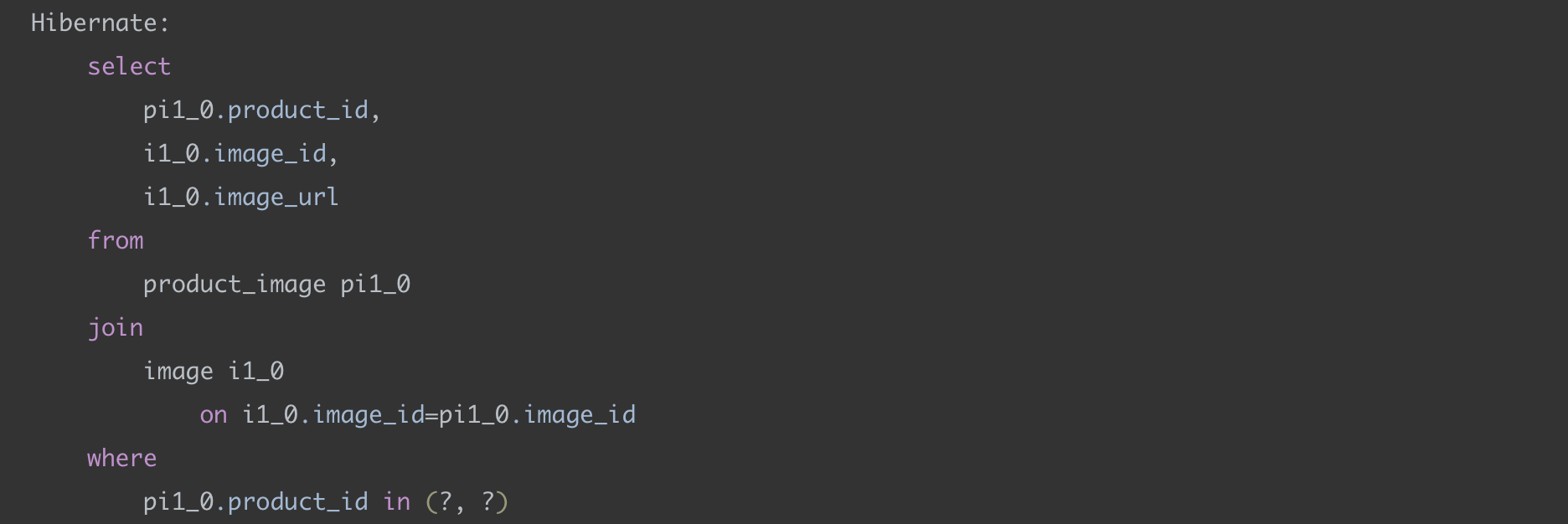
두 번째 쿼리에서는 첫 번째 쿼리에서 조회된 product_id를 가지고 in 쿼리를 날린다. 이를 통해서 product_id에 속하는 모든 이미지를 가져온다.
toProductIds

1번 쿼리에서 조회한 product_id를 추출해서 리스트로 반환하는 메서드이다.
(3) 상품 - 이미지 매핑 작업
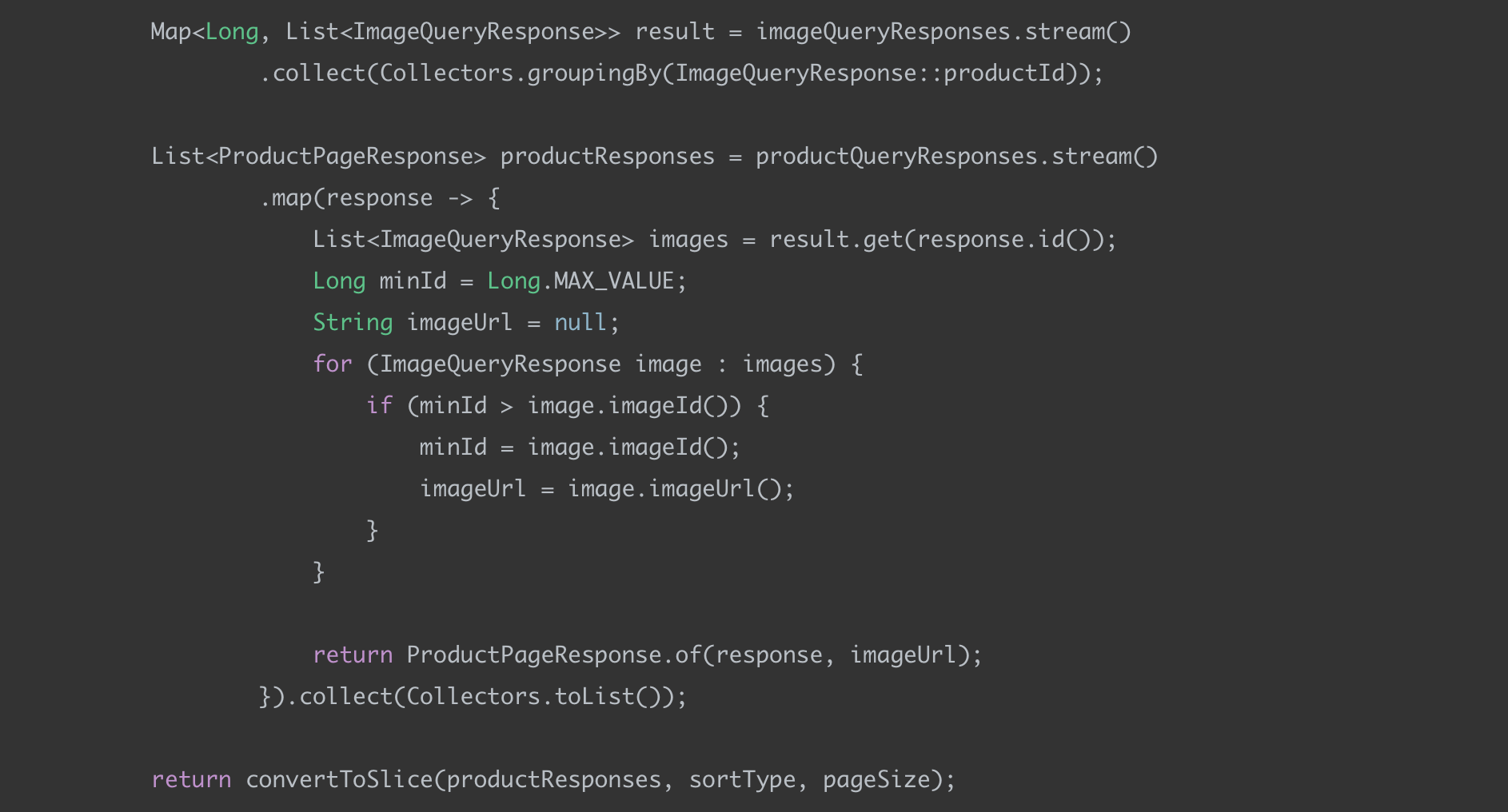
각 이미지 조회 결과를 product_id 키로 묶고 대표 이미지를 뽑아서 최종 상품 리스트 응답 값을 생성한다.
converToSlice
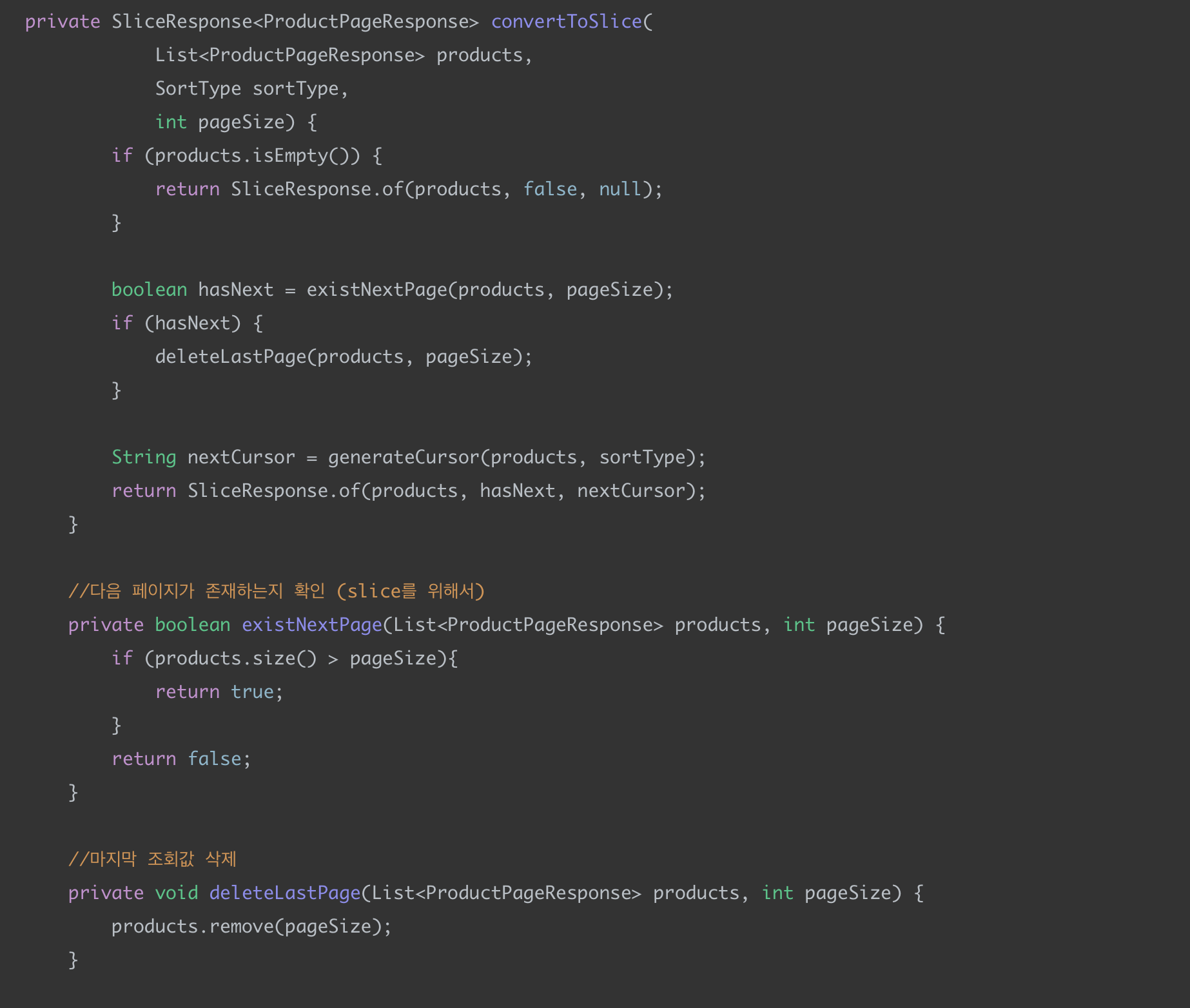
마지막으로 상품 리스트 응답 값을 SliceResponse로 감싸는 부분이다.
커서 기반 페이지네이션 처리 이후 쿼리 (결과)
SortType = LATEST (최신순) 테스트
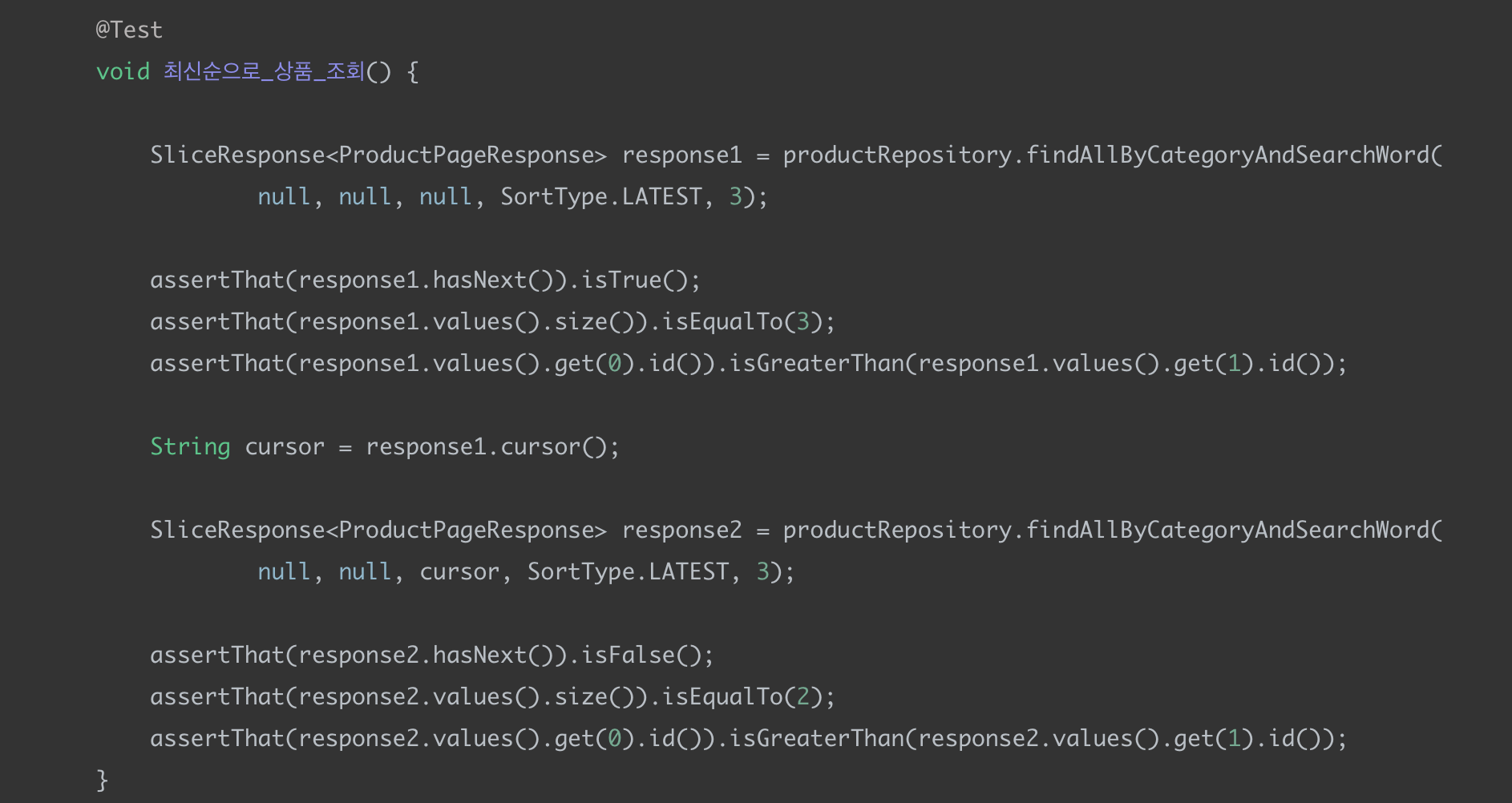
쿼리
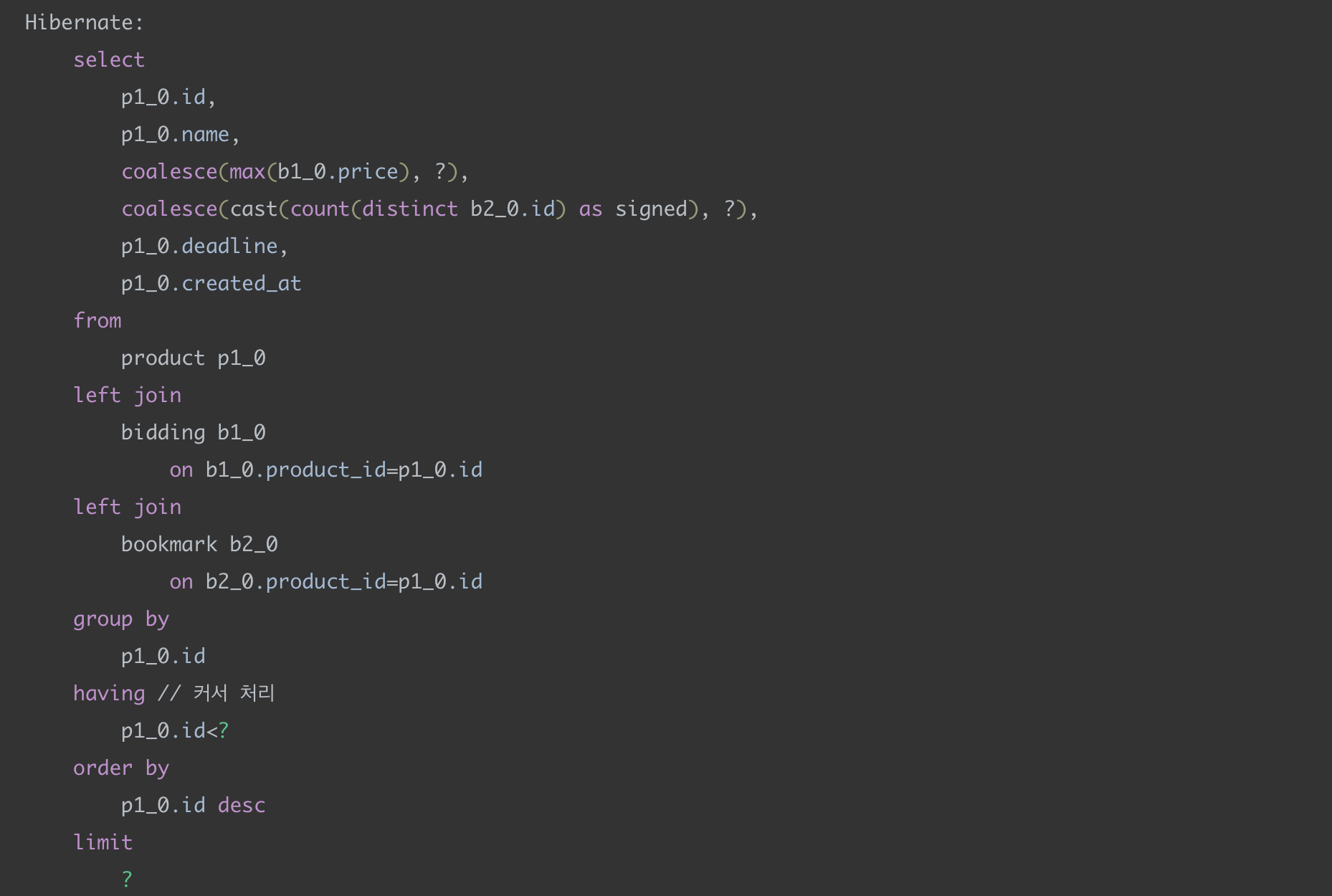
총 2번의 쿼리가 나가고 첫 번째 쿼리에서는 having 절에 커서(product_id)를 기준으로 조회가 되는 것을 확인할 수 있다.
두 번째 쿼리에서는 in 쿼리로 이미지가 조회되는 것을 확인할 수 있다.
SortType = HIGEST_PRICE (입찰가 높은순) 테스트
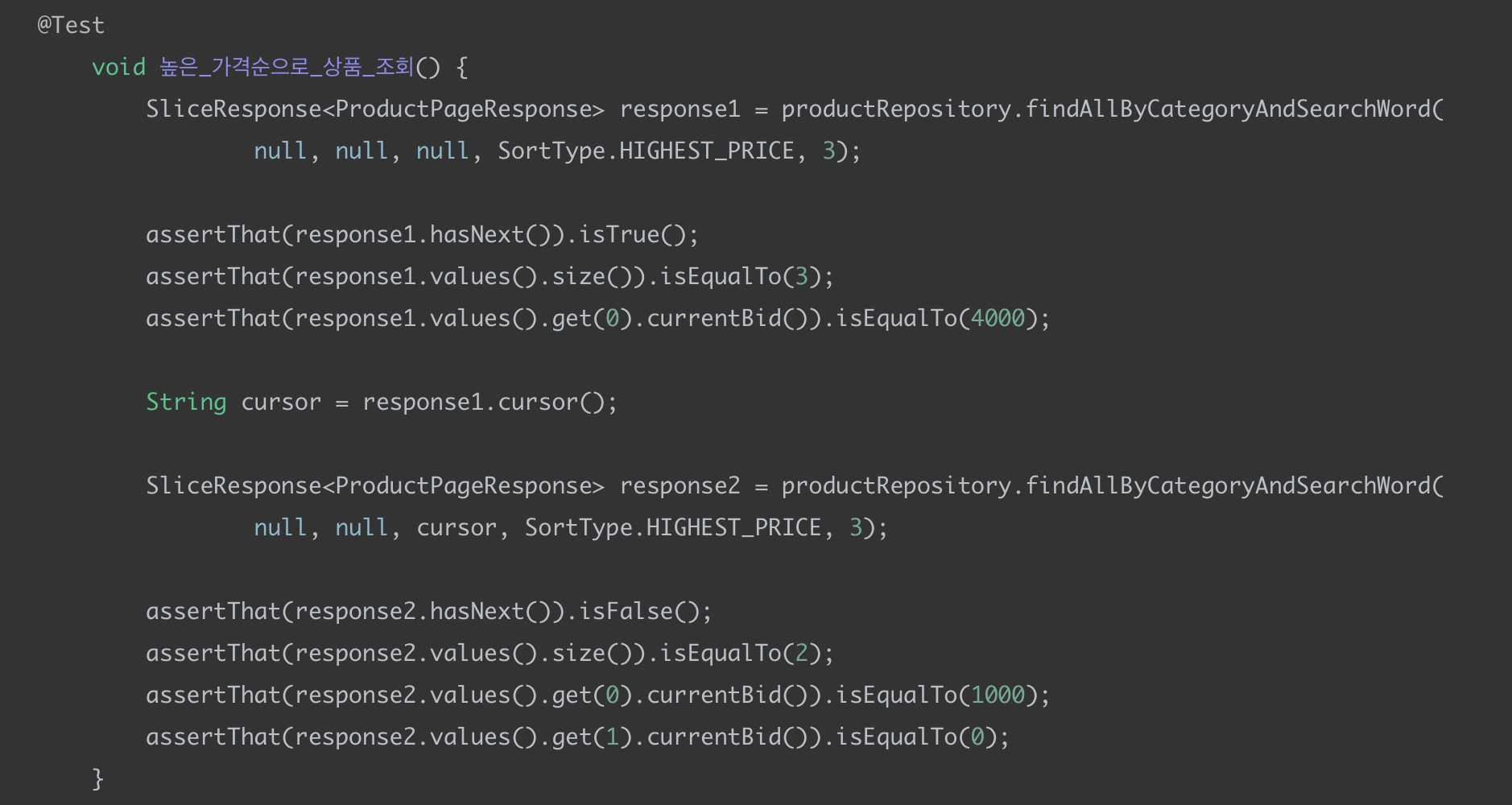
쿼리
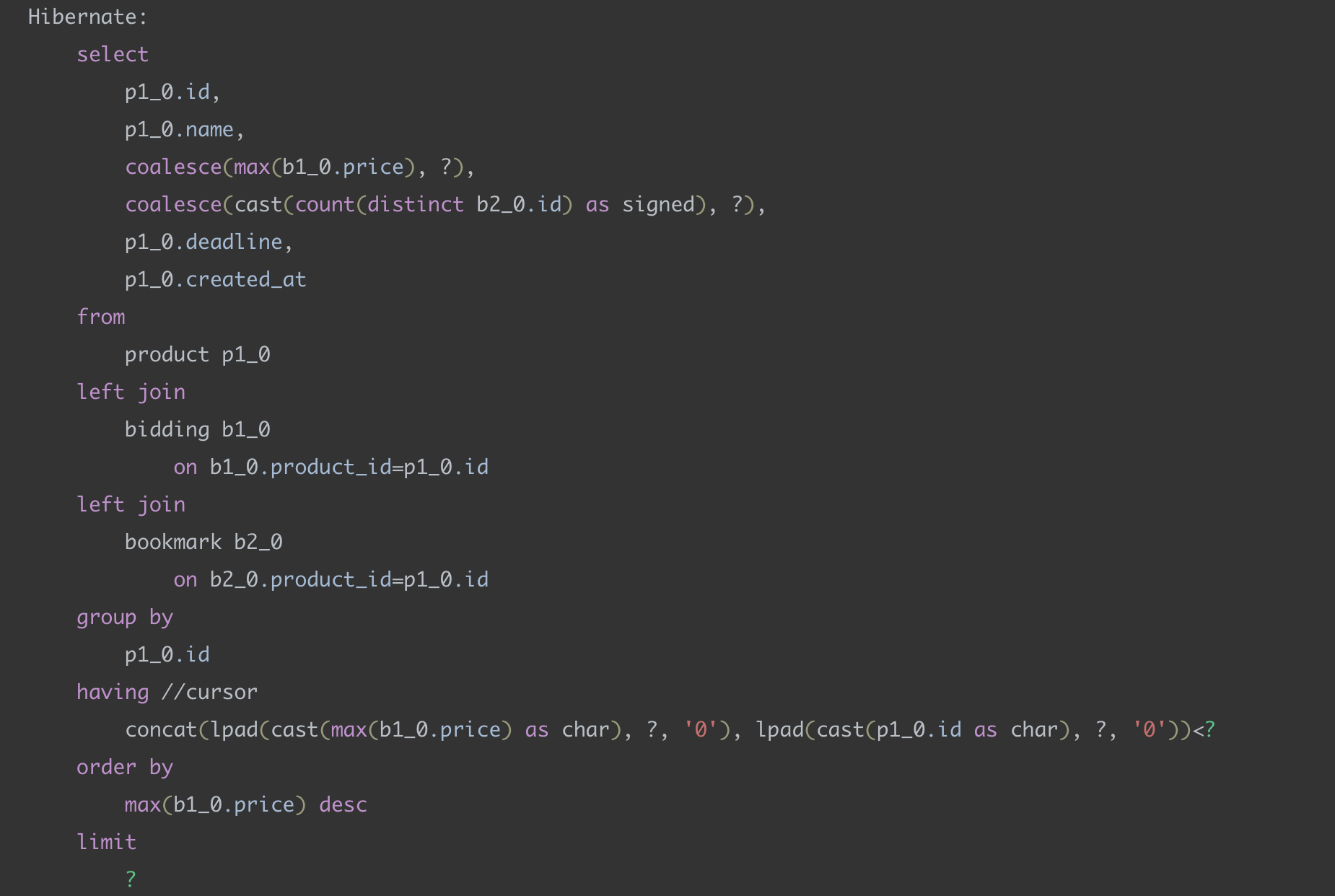
달라진 부분은 having절이다.

CONCAT과 LPAD를 사용되어 커스텀 식별자가 생성됐고 이를 커서와 비교하는 것을 확인할 수 있다.
SortType = BOOKMARK (북마크순) 테스트
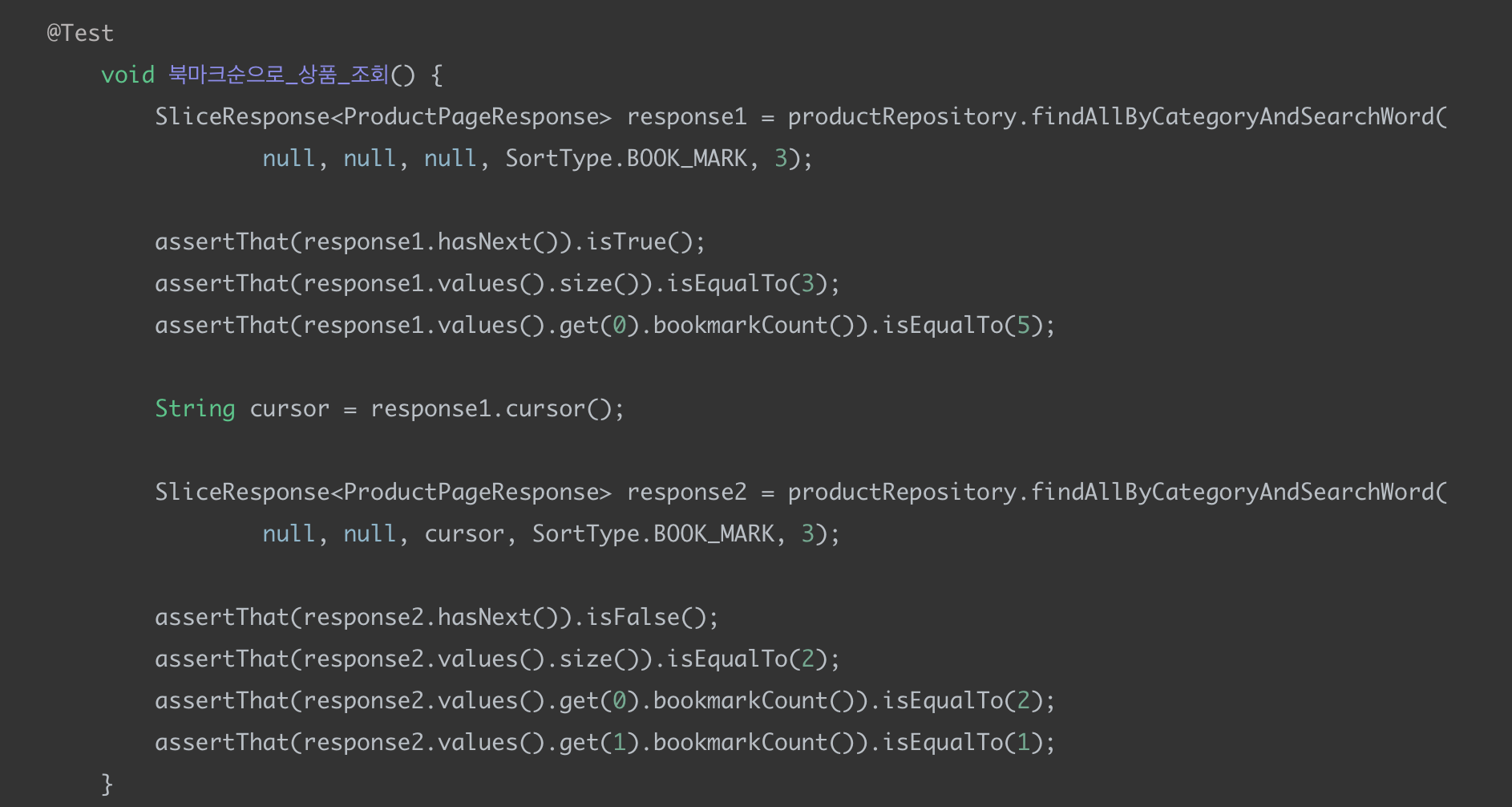
쿼리
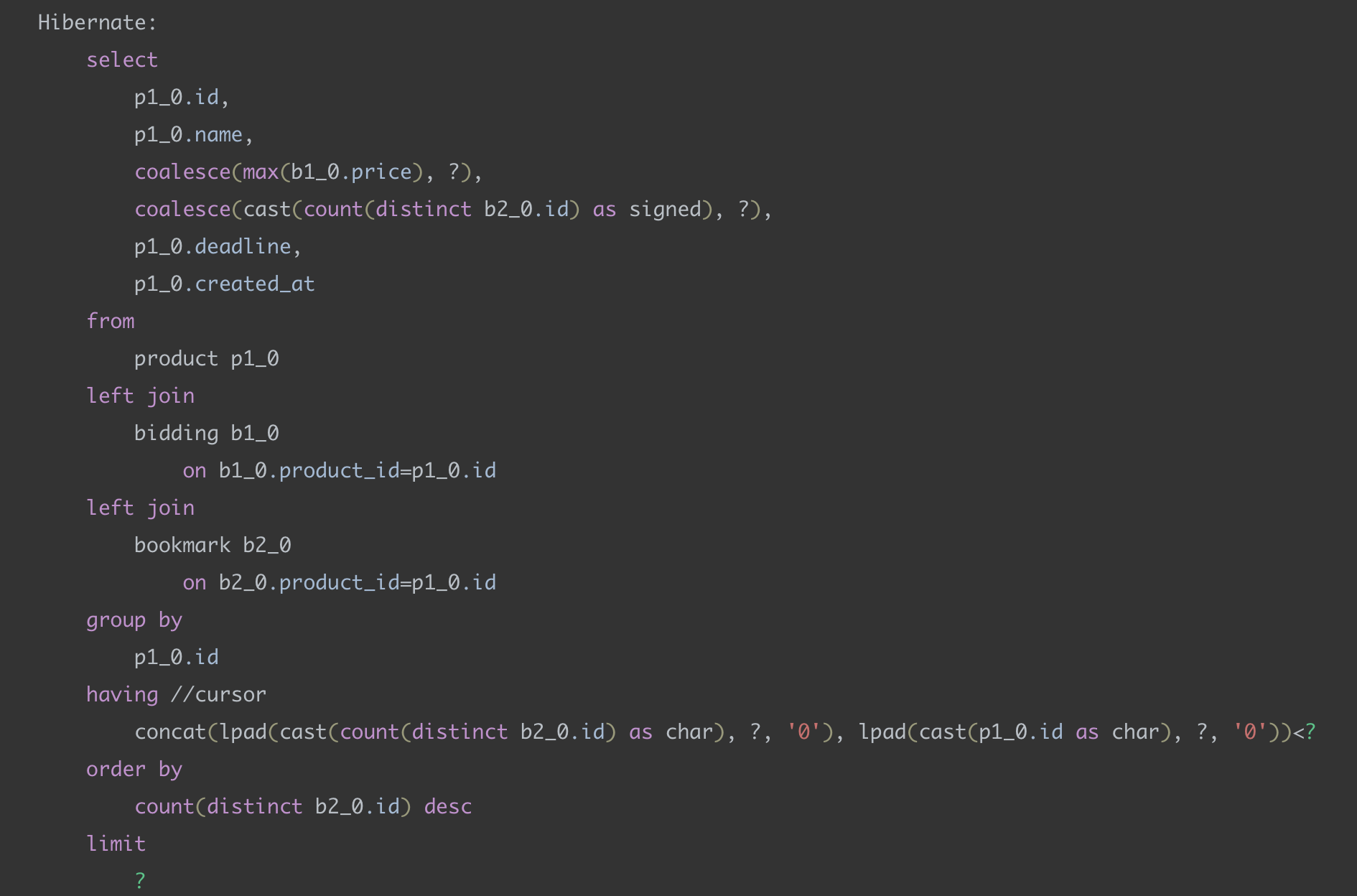
북마크도 마찬가지이다.

달라진 점은 패딩을 하는 값에 북마크의 수가 들어간다는 점이다.
테스트 결과
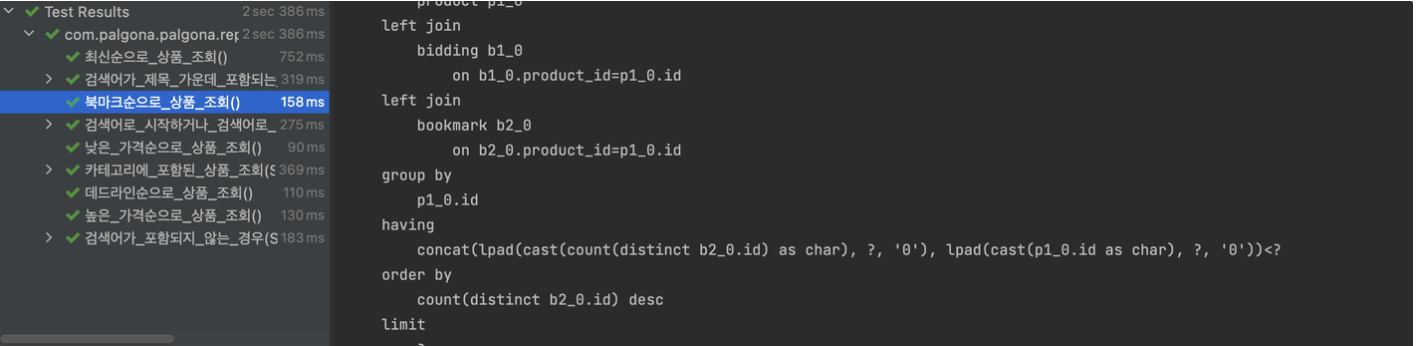
최종적으로 모든 테스트를 통과한 것을 확인할 수 있었다.!!
느낀점
중간에 키가 중복돼서 중복 조회가 발생하기도 하고 Querydsl에서 SQL 함수를 쓰는 방법을 몰라서 많이 헤매기도 했었다. 힘들었지만 테스트의 녹색불을 확인하니 너무 뿌듯했다!!